By Deb Radcliff, Evangelist, Bolster
I consider myself one of the first (if not the first) cybercrime investigative beat reporters for the business community. My eyes were opened back in 1995, when working as investigative reporter on a best-selling book about hacker-on-the-run, Kevin Mitnick, and I’ve been prolific on the issue ever since.
When I wasn’t dodging organized crime threats and fielding dicey sources (aka gray hats, vigilantes, bad guys turning on each other, etc.), I was doing my own research into criminal websites through rudimentary web investigations.
It was harder to tell what was real or not on the world wide web back then, and discovery tools were few. WhoIs lookup became my most important tool to learn about the intention of fraudulent sites I dug up during investigations.
Time and Persistence
The tool back then wasn’t much different than now – it gives basic information on the domain, subdomains (sometimes), the registrar, the site server administrator (because back then every site was tied to a specific server and there was no cloud), and so on. All of this was manual and involved typing in variations of a URL and IP addresses in the WhoIs lookup one at a time.
Nothing was easy or as visual as it is today on the Web. Not everyone registering their sites was truthful about who owns the servers, but they had to provide contact information that a valid registrar would accept. More often than not, the server’s listed administrator was also a third party, which then required more WhoIs lookups and on and on.
The process could have been so much easier if only it were automated! We had some of the technology to do this back then, such as web crawlers (which were early day tools of hackers only, and extremely slow compared to today). And the WhoIs tool, which as explained, was tedious and manual.
Fraud and eCommerce Intertwined
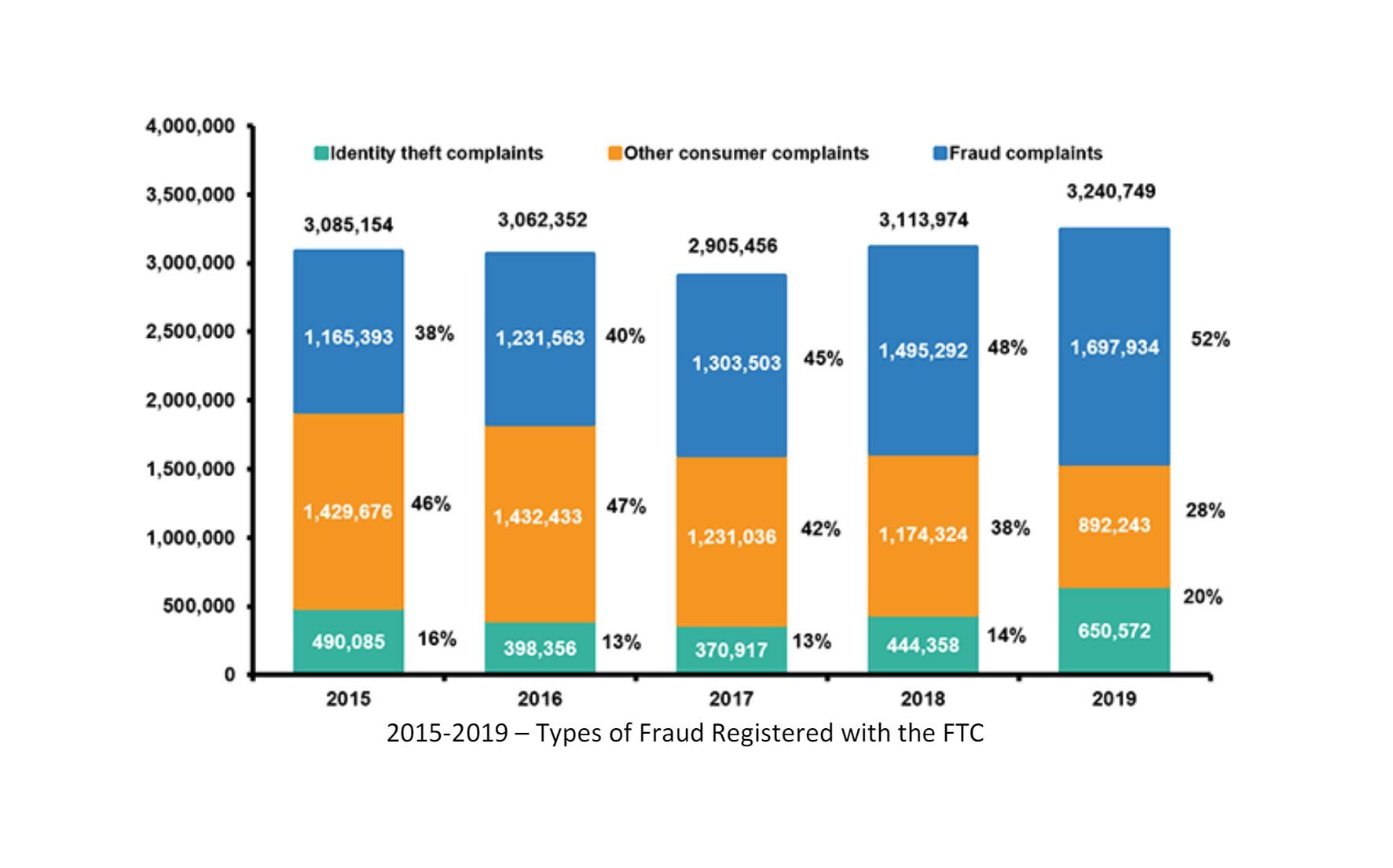
As the Web grew, so did e-commerce fraud.
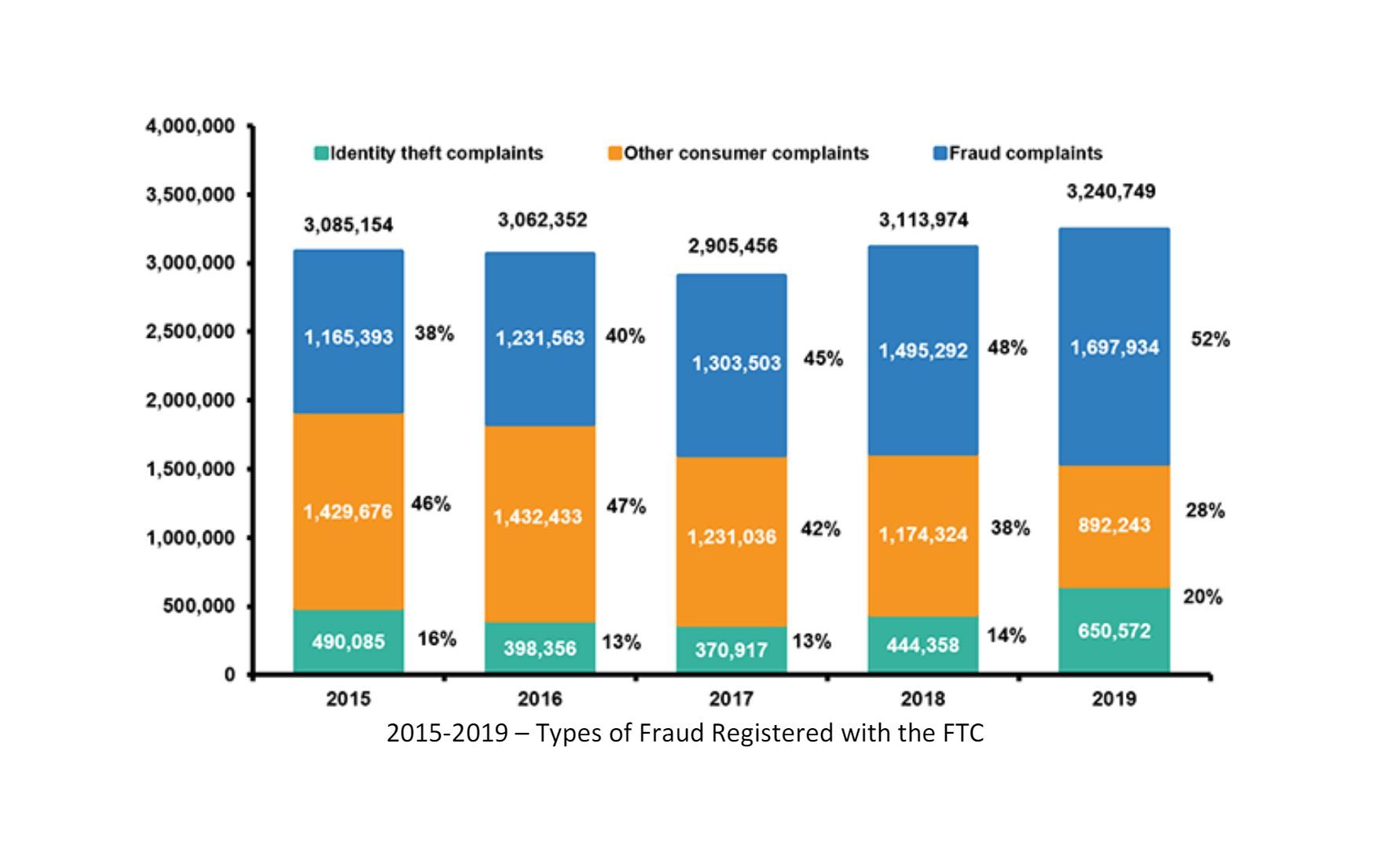
Cybersquatting on brand names and variations of brand names was the first indicator of growing forms of fraud aimed at a brand’s customers. And now, there are millions of fraudulent sites selling knock off goods and pharmaceuticals (enabling a $300 billion counterfeit goods market), while phishing has become much more sophisticated and continues to spread as scammers take advantage of dozens of new top level domains (.info, .uk, .olive, .me, etc.) to impersonate brands.
Most customer-facing businesses with a web presence today are aware of the loss of revenue and customer confidence resulting from eCommerce fraud. And many are pursuing means to reign in the fraudulent sites.
While legacy brand protection tools can automate some of the search and even provide basic analysis on the nature of the site, meantime to take down these fraudulent sites still takes weeks, in some cases months, because of jurisdictional issues and slow response on the part of registrars and hosting providers.
Why I Chose Bolster
When I learned how Bolster automated all these processes and applied intelligent and machine learning to vetting the criminality of these sites, taking a job with Bolster was a no brainer.
Over the course of my career, I’ve never seen a platform that can provide solid, evidence-based analysis the way a human would on brand abusing sites. And, that analysis is so well vetted that most of the top registrars and hosting providers trust the information enough to work directly with Bolster (through API integration) to automatically take down fraudulent sites in seconds instead of weeks, or even months. To me, this speed to take down is critically needed and entirely unique.







