Computer vision modules are a critical component in a cybersecurity workflow, especially in the context of protecting organizations from phishing and scams. Computer vision modules help in detecting discrepancies for logos, favicons and website user interfaces to verify the authenticity of the brand and protect your company value. These modules often rely on other data analysis paradigms, like machine learning and dimensionality reduction, to draw important inferences from the image data.
At Bolster, we have been deploying computer vision solutions to detect hacker’s malicious attempts to steal our customer’s brand data through logos, favicons, and other brand impersonation attacks like copying similar looking layout designs to original websites owned by the customer. The emphasis is to collect and use image datasets to train convolutional neural networks to detect discrepancies between genuine websites and the impersonating entities (also known as typosquat domains).
One of the ways we are using computer vision at Bolster is to conduct image detection with our webpage screenshots. We use encoding methods to extract a system-level representation of the webpage screenshot images from millions of websites, sourced by Bolster AI’s exhaustive scan engine, and create an expansive database of their encoded representation. This database is then used to conduct searches and fetch the brand intel for the closest matches.
Computer Vision Hashing
With phishing detection, our aim is to build a software pipeline capable of detecting the intended brand representation of a webpage by processing its screenshot image.
There are a few ways to do this; we went ahead with the database-search method to detect the brand. The idea is to convert the image into a hexadecimal encoding, via hashing techniques. The encoded representation is unique to the image, and is a direct representation of the image features.
This technique is pertained under the dimensionality reduction paradigm, where the high dimensional image is projected to a unique lower dimension hash.

This hash can be stored into a lookup table or a database to create a expansive dataset for millions of screenshot images of webpages on the internet. These webpage screenshots can then be reduced to a hash matched to their brand names inside the database.
Next, when a query image is received, it is converted to the hash encoding as well. This encoding is then treated as a query term for the database. The query term is searched for in the database, and if the query hash matches an existing hash in the database, the brand name for the existing hash is extracted and returned as the brand detection of the query image.
The advantage of the hashing technique
- No deep learning training required: Since the image is converted to a hash encoding directly and used for matching during query search, no extensive deep-learning model training is required. Deep learning training is expensive and required significant amount of resources.
- Quick search: The query image once converted to a hash is very quick to find in the database. The database can use various optimization techniques to speed up the search time. However, even in the worst case scenario, query search utilizes linear time complexity.
- No false positives: The hashing and search techniques always return a one-to-one exact match. This implies that if a match is found, it’s guaranteed to be a correct match. The hashes are matched with each other in absolute terms, which means a positive match is returned only if an exact match is found during the search.
The disadvantage of the hashing technique
- Non-meaningful projection: The hash representation of the image is to a large extent arbitrary, what this means is that similar looking image can have arbitrarily different hashes. Ideally, we would want similar looking images to have similar hashes with slight variations. This happens because hashing is not a meaningful projection of the image data.
- Low success rate: Although hashing technique never returns a false positive as it always returns an exact match if it exists, it is unreasonable to expect to find a correct match for every query. The search also fails a query image is very similar to one of the images in database but slightly changed (possibly due to a recent update to the webpage).
- Large database: The query needs to be matched to an existing entry in the database, however the database required to maintain a reasonable positive rate can be up in the order of a few hundred millions, maintaining such a large database is challenging and a burden on resources.
Deep-Learning Based Image Classification
Detecting brands can also treated as a image classification problem, and this is where the mighty deep learning convolutional neural networks come in.
The idea is to converge a universal function approximater, like a convolutional neural network, using a labeled dataset to capture the feature representation of the images in the dataset and train a classifier to map these feature representation to the brands.

Convolutional neural networks need a training phase to capture these representations using covolutional filter.
During the training phase, the model processes the entire dataset using a forward pass and backward pass repeatedly. In forward pass, the model produces a prediction for the given input image. The prediction is compared to the true label and the error between the prediction and true label is computed.
The loss then governs the backward pass, in which the convolutional filters are re-adjusted to produce a better prediction in the next forward pass.
This process is repeated again and again until model convolutional filters of the network represent the input dataset reliably, and produce accurate predictions thus minimizing the losses. Once the training phase is concluded, the model is deployed to make predictions on production data, and is able to make accurate prediction from the knowledge it gained during the training phase.
Advantages of CNN image classification
- High success rate on unseen images: CNNs tend to acquire a generalized low level feature representation of the images in the dataset. This helps the model recognize such patterns reliably even when there are variations in high level features such as website layouts. CNNs are a step in direction of artificial intelligence as they tend to perform reliably even when the input images are unseen during the training phase
- Meaningful representation: CNNs are good at clustering the similar features in similar images, which means the representation is meaningful and not arbitrary, this is exactly what helps CNNs perform well even on the unseen data.
- No database required: CNNs do not require to maintain databases in production. The image inputs are processed in end to end manner, which means image and the model are the only requirements to produce a reliable prediction. The CNNs also avoid any database searches, hence on disk memory constrains are less.
Disadvantages of CNN image classification
- Can make mistakes: CNN although reliable perform even on unseen data, but since the feature representations are learned, there is always the possibility of false positives and misclassification. The model needs bigger datasets and longer trainings to reduce these mistakes in production
- Bias: CNN are trained with objective to classify any input image to a class label instead of finding matches. The issue with this is that most real world dataset don’t represent some of these classes fairly. If the images belonging to some classes are significantly less than other classes, the model will be biased to learn to classify most images into the well represented categories and ignore the least represented categories.
- Computational resources: Deep learning models although do not need to maintain databases in the backend, they themselves require significant memory resources, these models are computation heavy with millions of parameters and convolutions to produce a prediction.
Image Retrieval with Similarity Search
An often overlooked method to conduct searches for images is the image retrieval method, which relies on similarity search. These models also require deep-learning models, but use them in a clever way to rely on similarity query search. The image retrieval method sits in the middle of the hashing method and CNNs, trying to utilize the advantages of both.
The image retrieval method, like computer vision hashing, also relies on projecting images to a lower dimensional feature representation and conduct a query search in the stored database. However, this method performs the projections of images to lower dimension in a more reliable and learnable way.
Each image of the dataset is transformed into a vector embedding which is an unique, one-dimensional feature representation of an image while keeping the track of brand label of the original image. These embeddings are stored as columns in a matrix, called search matrix, which is a 2 dimensional NxM matrix where N = length of vector embedding for each image and M = number of images in the dataset.
The image retrieval method conventionally uses a pre-trained deep-learning model, such as a CNN, to convert the input image into the feature embedding. The pre-trained neural network here has already been trained on a general purpose task beforehand and is capable of generating meaningful representation embeddings.

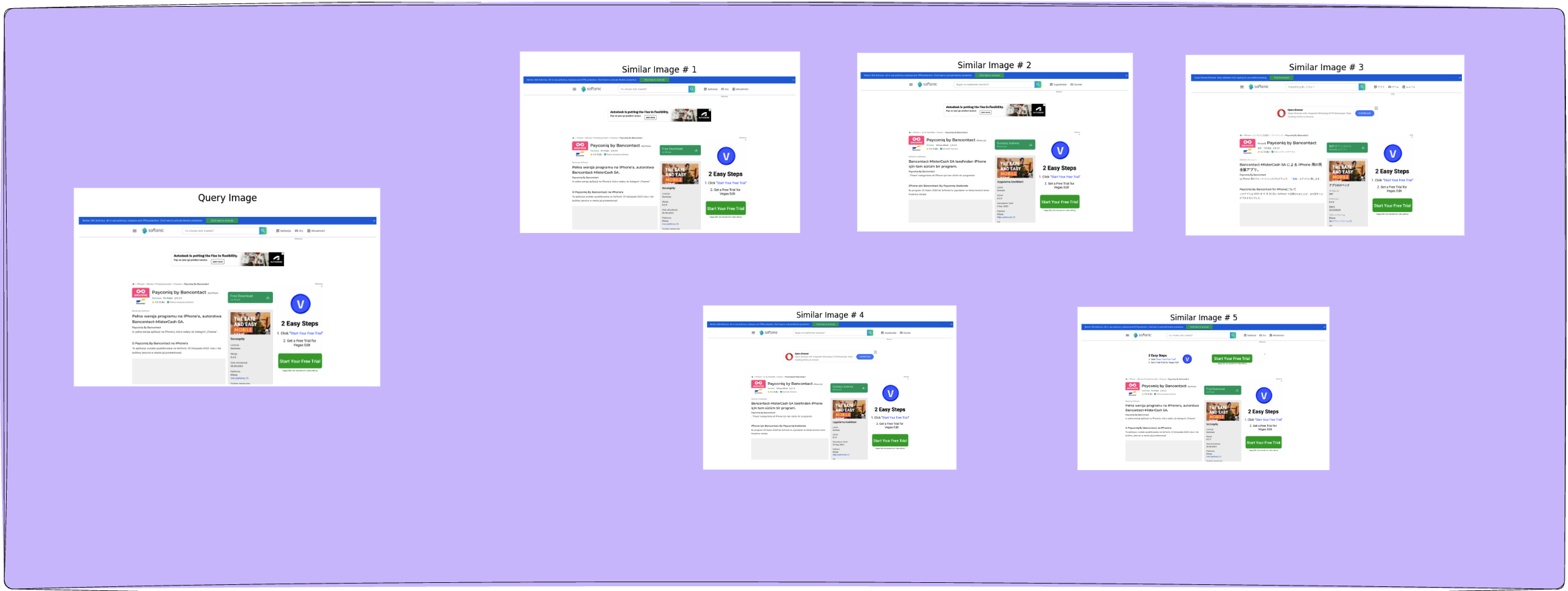
During the query phase, the input image is also converted to its vector embedding. This embedding is the query term to be searched with the matrix. The search is quite different from the hashing method, as it does not look for a match but tries to compute similarity scores with stored embedding.
The embedding with the highest score is returned as the match for the query and its brand label is returned as the detected brand ID.
The advantage of image retrieval with similarity search over computer vision hashing
- Meaningful representations: Since image retrieval uses learnable neural networks to produce embedding vectors of the input image, these embeddings are meaningful representation of the image. This implies that similar looking images are projected on to similar embedding vectors in the latent vector space. This allows similar embeddings to be clustered closely together.
- Similarity search: The similarity search, such as cosine similarity or manhattan distance, is a more reliable way of searching a match to the query embedding. This method does not look for a direct match hence even if the query embedding is very similar to a stored embedding, we can designate it to be a match. The meaningful representation makes sure that this match is accurate as the embeddings from similar images also lie close together in the projected vector space. This ensures that webpages even if not exactly same but still look similar are matched (which is the case in most real world scenarios), something that hashing method is not capable of.
- Faster search: The query search in image retrieval is actually a matrix multiplication operation rather than a linear search. The matrix multiplication is significantly less compute exhaustive as compared to linear search as machine learning libraries and hardware are highly optimized to handle matrix multiplication.
The advantage of image retrieval with similarity search over deep learning based image classification
- Unbiased learning: As mentioned before, the deep learning models trained for image classification tend to be biased towards well-represented classes and tend to perform poorly for the images belonging to less represented classes during production. The image retrieval method treats all the classes fairly. The similarity score is calculated against each stored embedding and even if a particular brand has only one embedding entry in the search matrix while other brands have thousands. Hence, if a query image has the most similarity with this one embedding entry, it is returned as the match. An image classification will very likely return a wrong prediction for a class which has only one example in entire training dataset.
- No training required: Training a neural network is an expensive process both in terms of effort and time, as the data has to be labeled and accelerated GPUs are required to train a model on large datasets in reasonable times. The image retrieval method however uses an off the shelf pre-trained neural network to only produce the embedding of the images in the dataset. This step requires no training and doesn’t need expensive backpropagation cycles.
Transformers and Their Potential in Computer Vision
Transformers have found great success in the field of Natural Language Processing tasks and generative AI. Transformers are a family of deep learning neural networks that was first introduced in in the paper Attention Is All You Need by Vaswani et al. in 2017. Transformers since inception have played the role of disruptor in the way deep learning models were trained for NLP tasks.
The original motivation of the transformers was to address the problem of RNNs not being able to capture global contexts in input sequences; transformers resolve this by using attention mechanism. The attention mechanism allows the model to break the input text sequence onto smaller tokens, and then attend each of these tokens individually to understand it’s relationship with each preceding token to understand global contexts. Weights of the models are adjusted according to relationship of each token to every other token.
Transformers exhibited revolutionary results in the field of NLP and is the very basis of advancements achieved in LLMs for generative AI. This success has tempted computer vision researchers to train transformer models for computer vision tasks as well.
This lead to the pioneering Vision Transformer, introduced in An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. As in NLP, the input is broken down into a sequence. For images, this is done by breaking the input image into 16×16 chunks.
This input sequence is attached to a position embedding to track positional information of the chunks. The sequences are fed to the encoder module of the ViT which containes multiple self attention heads. These attention heads pay attention to each of these chunks of images, find relationship with every other chunk. These relationships define how the weights will be adjusted in the transformer network.
The attention module allow the model to focus on separate set of features and their impact on other features in other chunks.

Vision Transformer have an encoder-decoder module; the encoder is responsible for converting an image to an embedding. This embedding is then utilized to train a decoder for the image classification task.
The encoded embedding serves as lower dimensional projection of the input image; this embedding is a direct feature representation and can be used to train parameters of the decoder for any downstream task. Not that this embedding is exactly something we can use as a query search to find the most similar match of the input image.
At Bolster, we have now deployed an Image Retrieval workflow that employs a Vision Transformer which is our solution to detect the brand for input screenshot images of webpages. This workflow allows us to use Vision Transformers, which are excellent at extracting meaningful representation of input images into embedded encodings.
This method also has significant advantages over standard Image classification, as it allows us to address the problem of long tail of poorly represented category labels of brands, in an extremely unbalanced dataset.
Our workflow
During the training phase, we use a pre-trained Vision Transformer model for its encoding capabilities. This model processes an input image through attention modules to produce an embedding of 768d. The embedding is stored in a search matrix as a column along with the webpage brand name as the level corresponding to the column. This search matrix is used during inference to conduct the searches.
For inference, the vision transformer again produces an embedding for the input inference image. The embedding is then used as a search query in the search matrix to find the closest match. This is done by using the cosine similarity method.
Cosine similarity measures the similarity between two vectors of an inner product space. It is measured by the cosine of the angle between two vectors and determines whether two vectors are pointing in roughly the same direction.
The query embedding is compared for best match to every embedding in the search matrix, and the embedding with highest cosine similarity score is returned as best match. The brand label corresponding to this best match embedding is then returned as the brand label guess for the input image presented for inference.
We have conducted experiments on three state-of-the-art vision transformer to find the best model for extracting the embedding during training and inference phases. These models are ViT-MAE model introduced in Masked Autoencoders Are Scalable Vision Learners , BEiT architecture introduced in the paper BEiT: BERT Pre-Training of Image Transformers and the SWIN model introduced in Swin Transformer: Hierarchical Vision Transformer using Shifted Windows.
Each of these three models are vision transformers and offer different advantages compared to each other. We go over each of these models briefly.
ViT-MAE

ViT MAE model was proposed with the motivation of presenting Vision Transformers as scalable learners. A significant damper on scaling vision transformer is the requirement of huge datasets to achieve the similar level of performances which CNNs can achieve with relatively much smaller datasets.
This poses a scalability problem, as its very uncommon for vision tasks to used huge dataset. The collection and labeling of image datasets is a serious overload on effort and time resources. ViT-MAE solves this problem by training vision transformers as autoencoders on masked image modeling task using self-supervised learning paradigm.
In the input image, 75% patches are randomly masked, encoder module of ViT only takes unmasked patches as input, and produces an embedding. This embedding is then concatenated with learnable masked image patch encoding.
The decoder then uses this concatenated embedding sequence to recreate the raw image pixels of the masked patche of the input images. The self-supervised allows for unlabeled dataset to be used, which alleviates the problem of requiring huge datasets, and makes vision transformers scalable.
BEiT

BEiT (or BERT Pre-training of Image transformers) was also proposed with the motivation to resolve the scalability issues of training vision transformers. Vision transformers require huge datasets and these datasets are impractical in computer vision tasks due to complicated labeling requirements.
Like ViT-MAE, BEiT also uses self-supervised learning paradigm to train a vision transformer on masked image modeling task. The model again possess a encoder-decoder structure.
However BEiT only aims to train encoder module. The masked image modeling training is also performed in a different way from ViT-MAE. For BEiT, input images are broken down to patches and 40% of these patches are masked. Both masked and unmasked patches are presented as input sequence to the encoder, unlike ViT-MAE where only unmasked patches are presented to encoder.
Another difference with BEiT is that it uses, an image tokenizer to generate visual tokens serve as label encoding against the encoding produced by the model, ViT-MAE on other hand uses raw image pixels as the label again decoder output.
SWIN Transformer

SWIN Transformer model was introduced with the motivation to draw the bridge between CNNs and Vision Transformers. The authors argue that there are key differences between language and vision data is of the variation in scale between image features and language tokens.
SWIN is a hierarchical transformer which address this problem of scale variation by computing transformer representation with shifter windows. The idea is to further divide usual image patches of input image to even smaller patches. These smaller non overlapping patches are then presented to attention layers.
The output from these attention layer are then concatenated in pairs to combine attention output the two higher level patches, this concatenated output is presented to next set of attention modules. This hierarchical propagation through attention layers, allows transformer to pay attention to smaller scale features and deal with variation in scales for image data.
Recommendations on How to Start Using Computer Vision
Computer vision is an important tool to protect against phishing and scams in cybersecurity. Phishing attacks deploy similar looking websites to deceive people to fall for scams on the internet. Computer vision helps in creating reliable pipeline to detect common patterns between similar looking websites and detect their brand.
One of the ways we internally at Bolster have been using computer vision hash matching to detect brands of the websites is by analyzing their webpages. Hashing techniques, although effective, only return an exact match, so if a webpage is changed over time this technique does not return a good match.
Image classification using neural network has proven to be effective tool in detecting patterns for brand detection of webpages. The dataset typically used for this problem is an extremely imbalanced dataset, and neural networks extensively struggle on such dataset.
Another technique to detect similar patterns is Image Similarity Retrieval, where we maintain a search matrix of images of webpages. In production, a query image is presented and searched for the best match in existing search matrix using a similarity algorithm. This technique is effective as even with an extreme imbalance; the best match, if it exists in the search matrix, is correctly retrieved.
Our pipeline integrates the Image Similarity Retrieval alongside the hashing search. To optimize storage of search matrix and query image search, images are encoded to embedding vectors using dimensionality reduction. Neural networks, especially Transformers, are excellent at encoding images and preserving their features into a embedding vector.
State of the art transformers like ViT-MAE, BEiT and SWIN transformers were deployed. As expected the results from these models are effective and solve the problem of brand detection in webpages reliably.
To learn more about how Bolster uses computer vision models and innovative generative AI to combat cyber hackers, request a demo with our team today.








