Midterm elections are just a few days away and the scourge of fake news and propaganda sites shows no sign of slowing down. In fact, the misinformation such sites have is getting far more challenging to detect with Artificial Intelligence based tools.
In order to highlight the problem, here is a quick quiz. Which one(s) of the following news headlines do you think are fake?
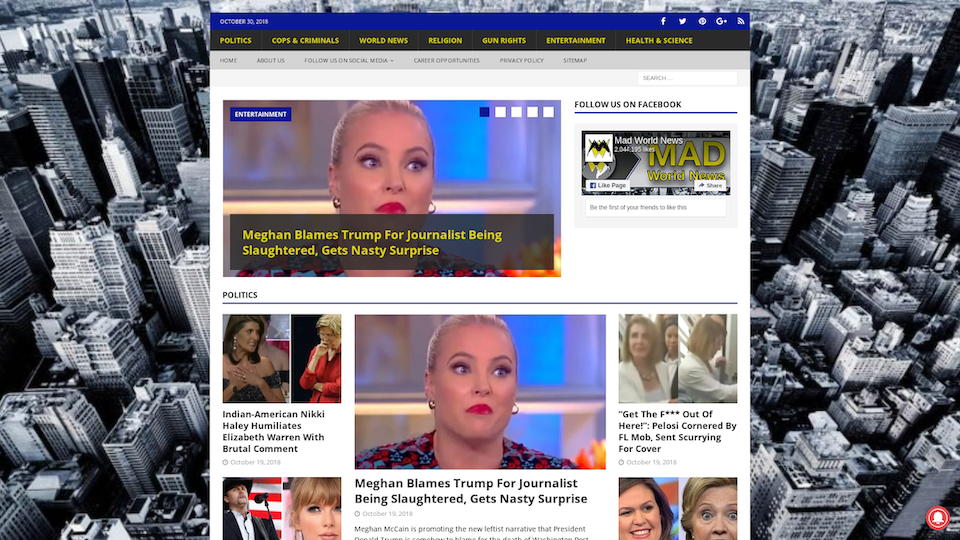
“Meghan Blames Trump For Journalist Being Slaughtered, Gets Nasty Surprise”
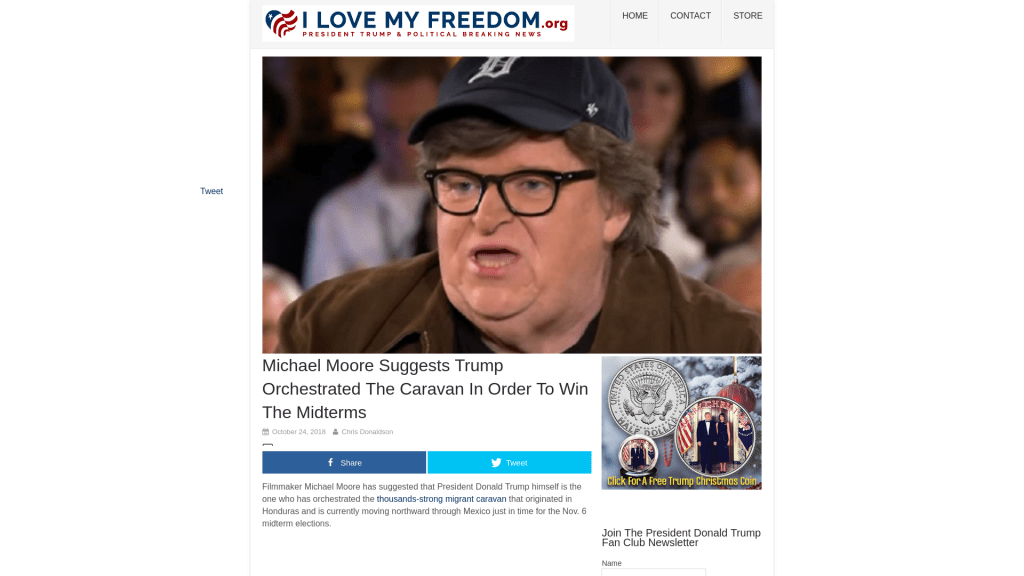
“Michael Moore Suggests Trump Orchestrated The Caravan In Order To Win The Midterms”
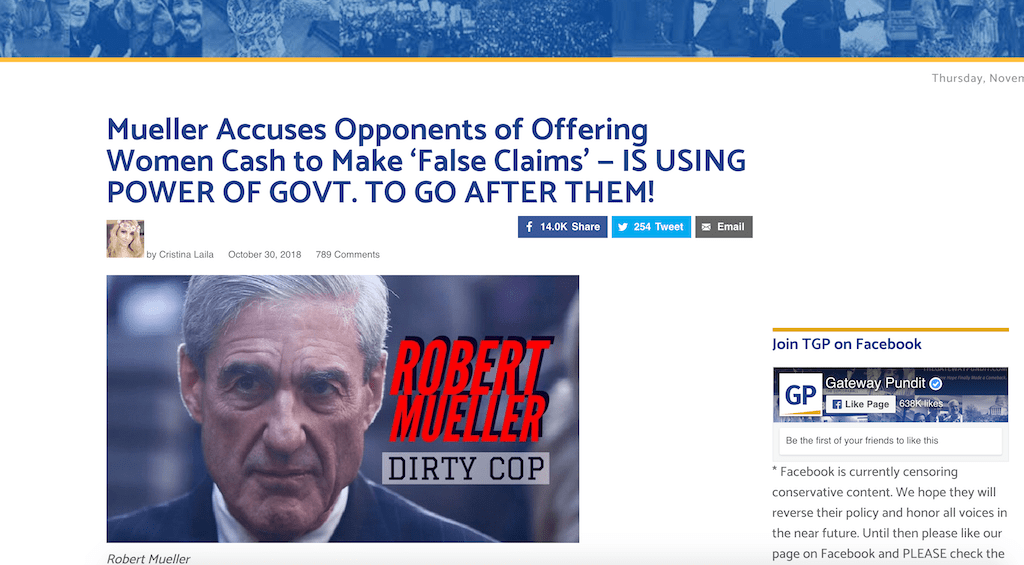
“Mueller Accuses Opponents Of Offering Women Cash To Make ‘False Claims’ — Is Using Power Of Govt. To Go After Them!”
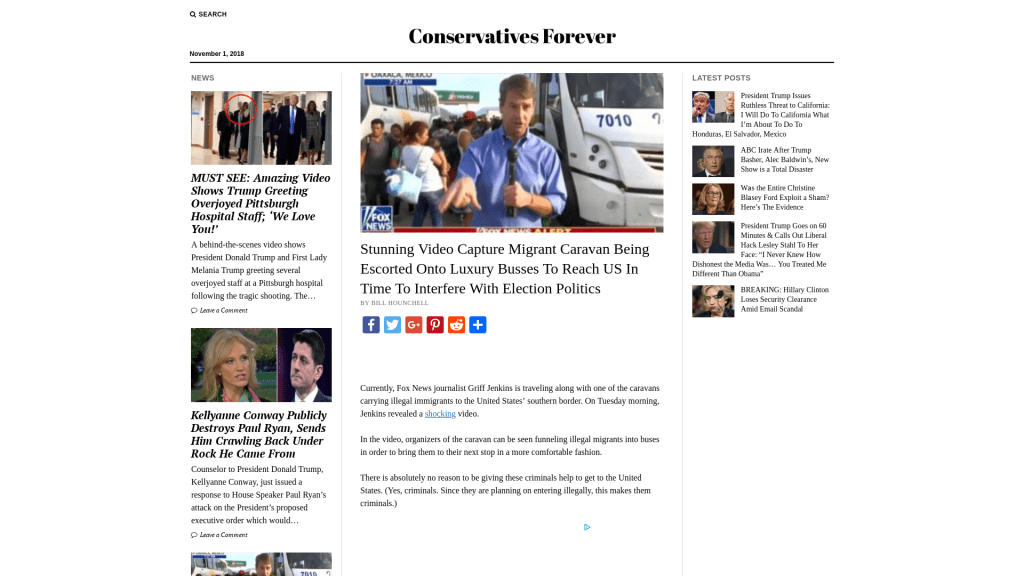
“Stunning Video Capture Migrant Caravan Being Escorted Onto Luxury Busses To Reach US In Time To Interfere With Election Politics”
As it turns out, none of them is true. The first headline is factually incorrect whereas the second, third, and fourth spin other news to change the original meaning of the story.
The problem of fake news has come to the spotlight only in the last couple of years, but it is getting harder for machines to detect with each new iteration. The language now is often a spin or misrepresentation of true facts rather than being factually incorrect, as it was in the past.
In this blog post, we look at how such websites are created and propagated to the masses and highlight deep learning and unsupervised learning techniques we’ve built at Bolster to detect them at scale.
In case you were wondering, here is what the websites with the above headlines look like:
How new fake news sites get traffic
At Bolster, we process links from 400 million+ spam and gray mail each day. As part of our pipeline, we store images and text of each website we scan. This provides us with the flexibility of doing extensive research on large volumes of information on demand.
Email and social media are the main sources of links to fake news sites. We observed several of these sites gaining traffic in the last six months (via redirect links). For example, blackeyepolitics[.]com had as many as 15 other websites redirecting to it, with over 5,000 unique tracking links sent via email in six months.

We also observed a strong correlation between traffic detected by our system and the popularity of the site as ranked on Alexa, showing that these sites are receiving a significant number of visitors and have effective methods of propagating content.


Some common characteristics we see in such sites:
- There is no information to identify ownership on the site (About Us, Office Address, etc.)
- The domain’s information in the WHOIS database is privacy-protected via proxy
- The hosting IP is either behind a reverse proxy (e.g. CloudFlare) or on cloud services (e.g. AWS, Google)
As you can imagine, it becomes hard to establish ownership and, as a result, authenticity of news articles posted on such sites.
Automated detection methodology
At Bolster, we are constantly working on innovative ways to quickly find interesting patterns in the websites we scan. We’ve been monitoring political websites in our data in the wake of upcoming midterm elections to find the ones with political and potentially fake content.
The scope of this research required experimentation at large scale and here are numbers to give you an idea:
- Pre-filtering 400M URLs per day with rules to reduce size of data set to 1M URLs per day.
- Assigning 100 – 500 abstract topics to generate interesting clusters for review.
- Sentiment analysis on filtered clusters to further narrow down articles with excessive negative content.

Step 1: Pre-filtering
This step involved removing non-interesting spam URLs from the dataset.
It turns out the ranking of URLs based on domains using Zipf’s law is quite effective in this stage. Domains that have the largest count in the clusters turned out to be usual spam links (primarily fake online pharmacy) and could be safely ignored. In addition to that, we filtered out some other non-interesting links based on keywords in site title.
Once we have the filtered dataset, the size reduced drastically to close to 1M URLs per day.
Step 2: Topic modeling
This step involved taking URLs from the previous step, getting the rendered natural language text from the html body and applying Topic modeling to them.
Topic modeling is an unsupervised learning technique to extract abstract topics from a given set of documents. For our task, we used a popular method called Latent Dirichlet Allocation (LDA). This method builds documents as distribution over topics and topics as distribution over words where the distributions are modeled after Dirichlet distributions.
Before applying LDA, there are few important pre-processing tasks required. This helps improve the quality of words used in modeling the distributions. We performed the following tasks on the data:
- Tokenization and pruning: Break the sentence into tokens (words) and remove tokens that were longer and smaller than certain thresholds. Also, remove common stopwords (the, an, a etc.) This cleaned up low quality and noisy tokens from the data.
- Lemmatization: Convert different morphological forms to the root word. For example, words `good`, `better`, `best` get converted to `good`
- Stemming: Convert different forms of a word to its root word. For example, words `claim`, `claimed`, `claims` would be converted to one token `claim`
We used the popular NLTK library in Python to perform the above tasks. Now that we had a clean dataset, we used another popular Python library – gensim, to create the input matrix and perform LDA on it. We tried both bag-of-words and TF-IDF matrices as the input for LDA out of which, TF-IDF gave us the best results.
Topics created
Below are examples of some abstract topics generated from our dataset along with token composition:
- Topic1: news, fox, trump, politics, entertainment
- Topic2: democrats, trump, reply, vote, pm
- Topic3: contribution, actblue, card, gifts, deductible
- Topic4: information, data, services, business, market
As can be seen from the topics above, Topic4 is different from the rest of the topics, that look like they are likely related to politics. Once such topics are assigned to documents, it becomes easy to cluster them based on Topic IDs. The cluster examples shown below were created by clustering based on such election/politics related topics. Note that at this stage we don’t know if the sites are serving fake news. Nevertheless, these clusters are interesting and worth highlighting.
1. Fake Daily Mail websites
This cluster consists of thousands of websites mimicking the Daily Mail news site. We found a total of 4107 websites registered between June 2018 and August 2018 on TLDs .cf, .ga, .ml, .tk and .gq.

2. Fake Wikipedia websites
Similar to fake Daily Mail websites, we found thousands of fake Wikipedia Articles on the same TLDs mentioned above.

Step 3: Sentiment analysis with LSTM
Once we have clusters of interest, we classify documents in each to see whether they have a positive or negative sentiment. This helps narrow down potentially bad websites spreading fake news or propaganda, as such sites tend to have overly-negative sentiment.
We chose LSTM for sentiment analysis because of its high accuracy in several NLP related tasks. We used Keras to implement it along with training data obtained from tweets on GOP debate during August 2016.
Here are some of the websites our model categorized with negative sentiment:

What’s next
It is worth mentioning that sentiment analysis provides a good filter to detect sites with excessive negative content. However, more work is required to determine whether the content is truly fake. For this research work, we used reputation of hosting infrastructure as one technique for detection.
When it comes to news, it helps to review several sources to confirm key facts, and we’re continuing to enhance the abilities of our system to detect false claims accurately. We believe a combination of source reputation and fact checking with Natural Language Processing techniques is right way to go when it comes to ranking fake news sites for “fakeness”.
Domains from this post with deeper insights on CheckPhish
References







